Exploration of Generative Music Approaches
- December 2019
This project explores the capabilities and limits of machine-learning-based approaches to generative music. It is a deliverable for the class Machine Learning.
The Basics of Generative Music
The term generative music describes music that is created by a system, often algorithms. In my particular case, I used different algorithms to generate music based on specific pieces. The different approaches to generative music can be categorized accordingly to their ability to create musical compositions. The musicality of the algorithm, therefore, depends on its ability to follow musical short-term rules as well as musical long-term logic.
If a model cannot create musical long-term structures, the generated composition might sound like it is “noodling”, due to the lack of overall coherence. However, long-term arrangements build on other musical requirements that need to work reliably before they can express their effect. In most of my generative approaches, I trained my model with a song that I sought to imitate using an algorithm. A model resembled a song when it took up musical motifs from the original song as well as short melody progressions that were distinct for the training song. Most models did naturally pick up the harmonics correctly when subtle or no key changes took place.
To make all models musically sound, my models considered three out of four main properties of musical sounds:
- Pitch
- Dynamic
- Duration
Tone Color
While tone color is an essential part of musical sounds, I limited my project to the generation of MIDI-files, which are loosely the digital equivalent to written score. The tone color (or instrument choice) is in the hands of the interpreter. The synthesis of instrument sounds is another area that is heavily being explored through new machine learning technologies. Check out the GANSynth Google Colab instrument synthesis notebook.
Different Approaches
The following machine learning approaches explore the different capabilities of current generative music attempts. For my first attempt, Markov chains, I used the visual programming software Max/MSP, which is commonly used for music and media development. A program created with Max/MSP is called a patch. For the more complex models, I made use of the open-source Python library Magenta Tensorflow. I used an attention-based algorithm that was particularly good at implementing long-term structure
Markov Chains
A Markov chain is a stochastic model that describes the probability of transitioning from one state to any other state of the system. Depending on the Markov chain's depth, the likelihood of transition to another state depends on a fixed amount of preceding events. For most of my generative compositions, I used a depth of six, meaning that the algorithm chose the next note based on the last six notes played. The higher the depth, the more similar the composition sounds compared to the original training piece.
Markov chains are good at finding motifs and small recognizable musical patterns. However, they lack the ability to create long-term structures. When they create them, they create them in an inconsistent, not necessarily musically logical pattern. I used the software Max/MSP to generate music in real-time after I had trained the model with a MIDI-file. Max/MSP offers an intuitive visual programming interface. I decided to use Max/MSP over Python as it allowed me to adjust parameters in the profram flexibly, create MIDI-signals in real-time, and easily integrate it into other projects. I created Markov chains with the user-added ml.markov object [5].
This is the original MIDI-song that I used for training the Markov chain. Please note that this is a recording of a MIDI-file that is played on a virtual keyboard. The tone color (piano sound) is arbitrary. (Please note that this won't play on iPhones) Avril 14th by Aphex Twin:
Simple Version - Pitch, Dynamics, and Chords
The first version of my Markov chain did only consider pitch, dynamics, and chords when being trained. I started the generation of music by giving it the first note of the piece, and it successfully generated new notes with varying pitch and velocity. As I implemented chord recognition into the Max/MSP patch, it played chords as well as single notes. Notes and chords were generated every 200 milliseconds. There were no pauses. As you will clearly hear, however, the generated music lacks any duration changes, which makes listening to it a strenuous experience. Listen to the recording below to get a feeling for the musical quality of a generative piece that does not consider pauses and the length of notes. Simple Markov chain generation (velocity, pitch, chords) based on Avril 14th by Aphex Twin:
Sophisticated Version - Pitch, Dynamics, Chords, and Duration(!)
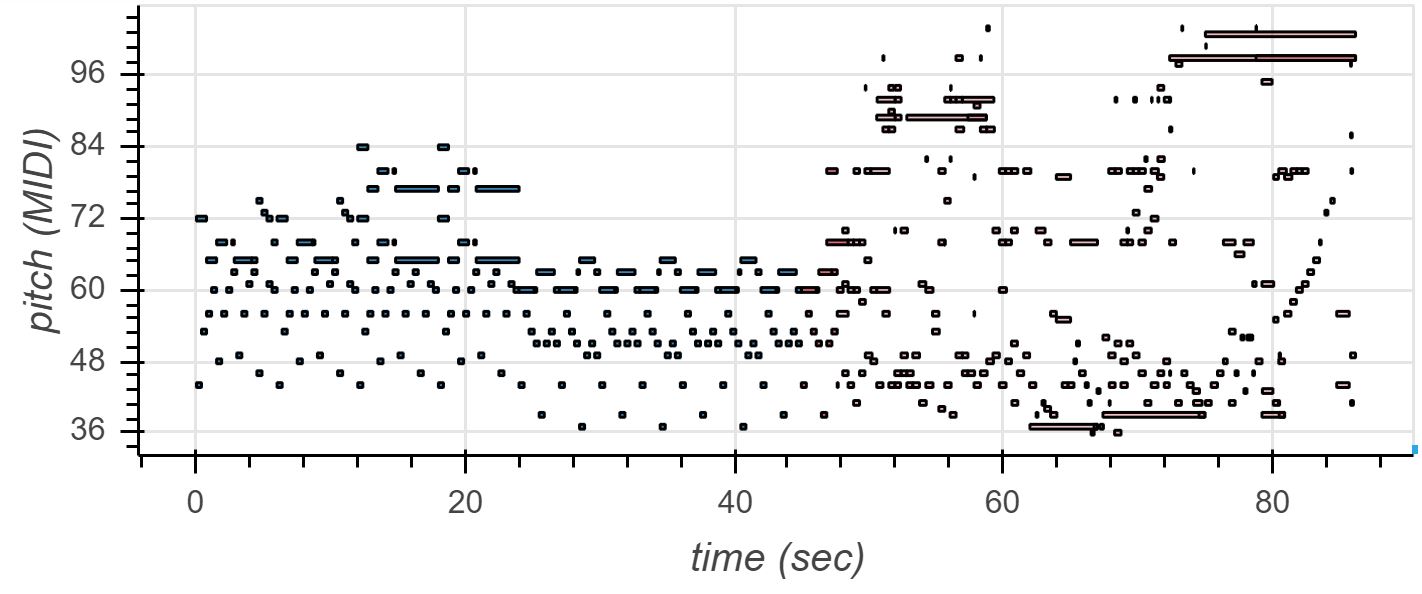
As you must have noticed, the previous recording is barely endurable. I improved the Max/MSP patch by filtering out the length of notes and pauses and trained another ml.markov object with the same song as above. You can find an image of a part of the patch right below if you're curious what it looked like.
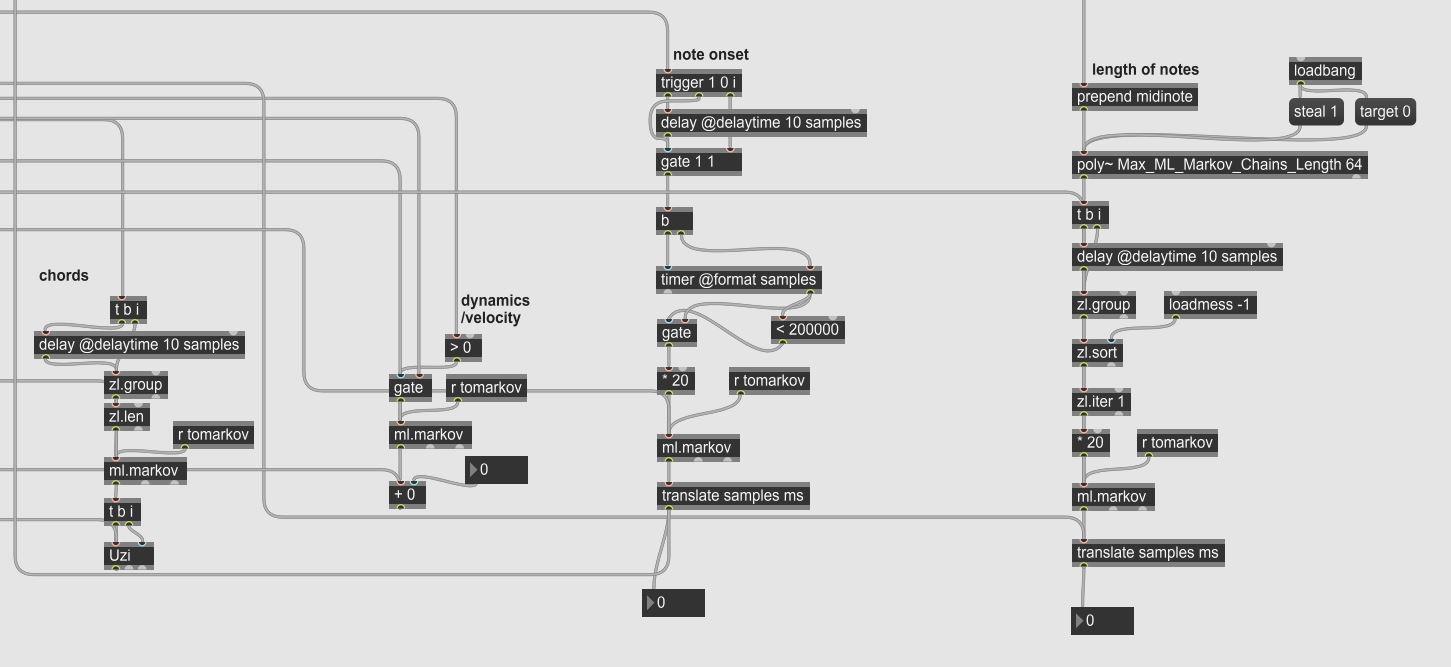
The final Markov model considers pitch, dynamic, and duration with a depth of six. I was quite fascinated by the musical complexity of the following recording. If you compare the record below with the first recording on this page, you will recognize similar motifs as well as longer melody patterns. The simple Markov model did also feature the generation of motifs. However, the implementation of duration and pauses brings the generated piece to another expressional level. Musical Markov chain generation (velocity, pitch, chords, + duration) based on Avril 14th by Aphex Twin:
Other Exampels
The example right below is generated with my Markov model. The following piece is the same piece that I used to train the more advanced model (read Music Transformer section below). Original Version of Violin Partita No. 2 in D Minor (BWV 1004) by J. S. Bach: Markov chain generated version of Violin Partita No. 2 in D Minor (BWV 1004) by J. S. Bach:
Transformer-Based Model - Music Transformer
The Transformer is an attention-based neuronal network that considers long-term and short-term structures. It uses expressive timing as well as an attention-based model that leads to improved long-term coherence. Expressive timing means that the model doesn not quantize the placement of notes. For instance, it might play a note slightly earlier than it is notated in the score. Expressive timing and long-term coherence were missing in the examples above. The transformer model, however, incorporates long-term structures by using relative attention, which means that it considers the length between two events. Due to this feature, it is able to pick up motifs and velocity progressions. It implements them skillfully in the generated score. Very recently, transformer-based models have proven to be more effective in language learning tasks. As transformer-based models work with relative distances when applied to language learning tasks, they are quite useful when applied to music. The Music Transformer remembers sequences and the relative position of notes, it gives them attention. The weight of single notes is affected by how much each other note affects the note. Consequently, the models only pays attention to significant events. The image below shows a visualization of the model-internal self-reference. The arcs represent which past notes informed the current note.Please not that the Music Transformer is not a recurrent model.
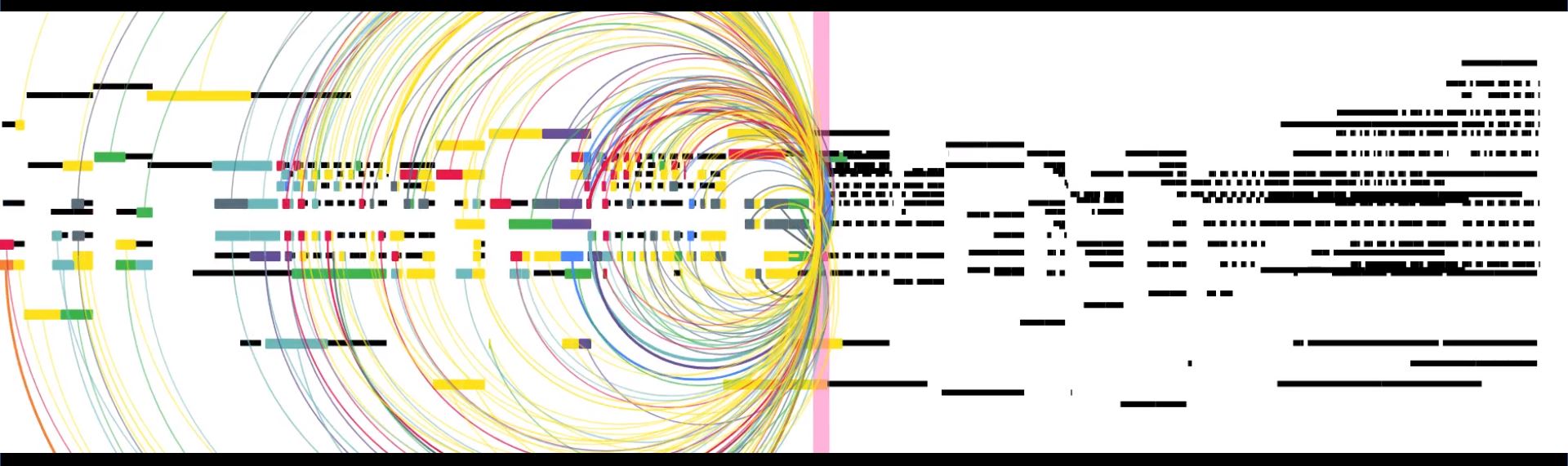
The Transformer model was trained on transcribed YouTube piano recordings. Consequently, its generated style shows similarities to these pieces. Its style does not work as well with modern classical pieces (if you're curious what the generative version of Avril 14th sounds like, check out the recording at the end of this section). Due to this reason, I used Bach's piece Violin Partita No. 2 in D Minor (BWV 1004) for priming the algorithm. The sequence that I used for priming the algorithm is right below. It was originally written for the violin. I used a version that was arranged for the piano to keep some amount of comparability among the examples on this page. Original Version of Violin Partita No. 2 in D Minor (BWV 1004) by J. S. Bach:
For the following generated example, I used a very long primer of 1:51 min in order to introduce characteristic features of the original piece before the algorithm took over. Skip to 1:51 min if you don't want to listen to the entire primer again.
Transformer generated version (start at 1:51) of Violin Partita No. 2 in D Minor (BWV 1004) by J. S. Bach:
![]()
If you want to learn more about the Music Transformer or just play around with it, check out this mostly well-working Google Colab notebook. Here is an informative article written by the creators of the Google Colab notebook. Since it is a pre-trained model, its generations have a quite "classical" character. I recommend using classical pieces as the training pieces.
Failed Transformer-Based Pieces
As mentioned above, the transformer-based model was trained on piano transcriptions. It consequently mimics the style of the transcriptions and doesn't work with pieces that show different characteristics. Here two small failures: #1 Failed Transformer Generation (start at 0:25) of Avril 14th by Aphex Twin: #2 (this one is fun!) Failed Transformer Generation (start at 0:16) of Avril 14th by Aphex Twin:
Sources
[1] Agnew, Sam. “Generating Music with Python and Neural Networks Using Magenta for TensorFlow.” Twilio Blog, Twilio, 18 Dec. 2018, www.twilio.com/blog/generate-music-python-neural-networks-magenta-tensorflow.
[2] Lin, Alvin. “Generating Music Using Markov Chains.” Hackernoon, 19 Nov. 2016, hackernoon.com/generating-music-using-markov-chains-40c3f3f46405. Pearce-Davies, Samuel. “Ml.markov Tutorial – Machine Learning in Max/MSP.” YouTube, 5 May 2019, www.youtube.com/watch?v=LG-GYFyJw74.
[3] Simon, Ian, and Sageev Oore. “Performance RNN: Generating Music with Expressive Timing and Dynamics.” Magenta, 29 June 2017, magenta.tensorflow.org/performance-rnn.
[4] Simon, Ian, et al. “Generating Piano Music with Transformer.” Google Colab, 2019, colab.research.google.com/notebooks/magenta/piano_transformer/piano_transformer.ipynb.
[5] Smith, Benjamin D. and Guy E. Garnett. “Unsupervised Play: Machine Learning Toolkit for Max.” New Interfaces for Musical Expression (NIME). Ann Arbor, MI: ICMA, 2012.